详解本地缓存技术 Caffeine
关键词:本地缓存;Caffine;Cache;Redis;多级缓存;二级缓存
简 介:缓存是高性能架构设计中不可或缺的环节。我们通常会将一些热点数据存储到基于内存实现的 Redis 或 Memcached 等缓存中间件中。这些缓存中间件往往基于内存实现,数据访问速度远高于基于硬盘的数据库(MySQL),从而极大提升系统并发量。然而,缓存中间件会带来网络开销,与本地缓存配合使用能够进一步提高系统性能,如Guava cache或Caffeine。因此,产生了使用本地缓存作为一级缓存、使用远程缓存作为二级缓存的两级缓存架构。本文主要介绍本地缓存 Caffine 的基本用法。
为什么使用缓存?
先复习一下,在计算机组成原理中学过,计算机有多级存储结构,数据IO最快的是直接与CPU相连的Cache,其次是内存,最慢的是硬盘,为了提高机器的运行速度,会先将硬盘中的数据读取到内存中,再将内存中的数据读取到Cache中,CPU直接与高速缓存Cache通信,这里内存和Cache的存在都是为了减少对硬盘的直接访问,因为硬盘IO非常慢。上述概念是一台单体计算机硬件的访存架构,对比来看,后端开发领域面临着同样的问题。后端程序往往将数据持久化的存储在MySQL或者Oracle等关系型数据库中,这些数据库虽然功能强大,但是却是基于硬盘存储数据的,后端程序每次从MySQL获取数据,都要承担高额的硬盘IO开销,这是高性能程序无法容忍的。
于是,参考计组的多级存储结构,很容易想到将从硬盘中读取到的数据存储到内存中,也就是缓存。缓存一般有两种,一种是运行在其他服务器上的远端缓存,例如redis、memcache,他们基于内存存储数据,具有较快的IO速度,但在访问时仍存在一定的网络开销。另一种就是将数据缓存在运行后端程序的机器本地内存上,这就是本地缓存,本地缓存不仅基于内存实现,还能避免网络开销,具有极高的数据访问性能。
企业实践中往往会同时使用这两种缓存,其中本地缓存作为一级缓存,远端缓存作为二级缓存,组成两级缓存架构,两级缓存的访问流程如图所示(来源csdn):

本文对redis、memcache等远端缓存不作过多叙述,主要介绍本地缓存。
本地缓存技术
尝试造轮子
已有许多的优秀的本地缓存库,例如Guava、Caffeine,但他们优秀在哪里呢?不了解本地缓存技术的细节以及痛点,你很可能只会使用Caffeine,而不知道为什么使用。所以这里简单介绍一下通用的本地缓存技术点。
所谓缓存数据,无非就是让数据驻留在内存中,想象一下,如果由你自己去实现一个缓存,你会怎么实现呢?最简单的,我们可以 new 一个 HashMap,然后将数据存储到Map中,后续获取时直接根据缓存的key值从Map中取出数据,时间复杂度是O(1)。
但是用这个Map来做缓存存在一个严重问题:数据不会自动remove掉。随着你一直往Map里put数据,Map占用内存会越来越大,最终导致内存溢出。你想到了一个粗暴的办法:每过一分钟自动remove掉 map.size()/2 的数据,直接解决了内存溢出问题。
但是问题又来了,有一些数据是被频繁访问的,无脑remove掉之后,程序就会去二级缓存甚至MySQL重新把它加载回来,你不仅白remove了,还造成了网络开销甚至硬盘开销。而另外一些数据可能这辈子就用了一次,但由于它运气好,一直没被remove掉,导致它持续占用内存。
于是你现在面临这样的问题:想用一个容器缓存一些数据,但又要限制住这个容器的体积,及时淘汰掉一些无用的数据,使得容器中保存的数据总是“最有用”的。也就是说,你需要一个【淘汰策略 】。
淘汰策略
Congratulations!庆幸的是,淘汰策略不需要你自己去想,已经有大佬想出来了很多淘汰策略,这里简单介绍几种淘汰策略以及实现方法:
LRU及其实现
LRU-least recently used-最近最少使用算法,是一种内存数据淘汰策略,使用常见是当内存不足时,需要淘汰最近最少使用的数据。LRU常用语缓存系统的淘汰策略。
LRU算法实现
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。如图所示:
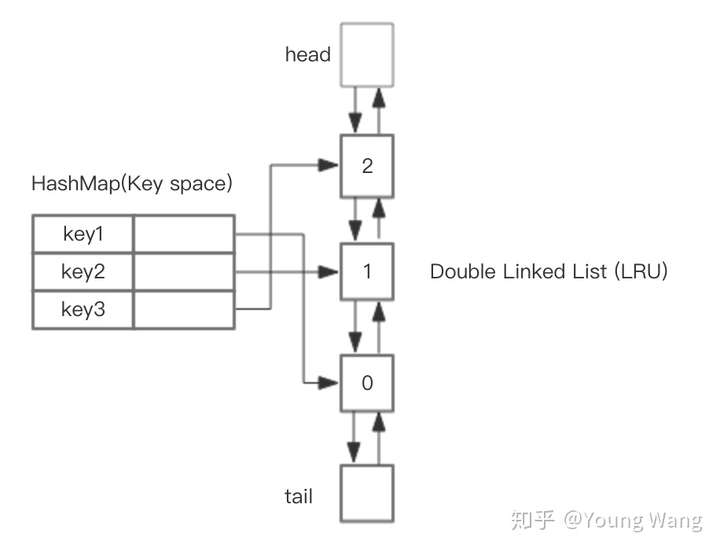 这样,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 O(1)O(1) 的时间内完成 get 或者 put 操作。具体的方法如下:
这样,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 O(1)O(1) 的时间内完成 get 或者 put 操作。具体的方法如下:
对于 get 操作,首先判断 key 是否存在:
如果 key 不存在,则返回 -1−1;
如果 key 存在,则 key 对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
对于 put 操作,首先判断 key 是否存在:
如果 key 不存在,使用 key 和 value 创建一个新的节点,在双向链表的头部添加该节点,并将 key 和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项;
如果 key 存在,则与 get 操作类似,先通过哈希表定位,再将对应的节点的值更新为 value,并将该节点移到双向链表的头部。
上述各项操作中,访问哈希表的时间复杂度为 O(1)O(1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O(1)O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O(1)O(1) 时间内完成。
源码如下(转自力扣):
1 | public class LRUCache { |
LFU以及实现
为什么要引入LFU算法呢?因为LRU算法淘汰数据的立足点是根据使用时间间隔淘汰数据,将当前内存中最长时间没有使用过的数据清理掉。这样就存在一个问题:如果一个不会经常使用的数据偶然被使用了一次,那这个并不被经常使用的数据就会一直待在内存中,浪费内存空间。如果我们想淘汰内存中不经常使用的数据,保留经常使用的热点数据,就要使用到LFU算法了。
LFU的全称为Least Frequently Used,意思就是最不频繁使用,所以,LFU算法会淘汰掉使用频率最低的数据。如果存在相同使用频率的数据,则再根据使用时间间隔,将最久未使用的数据淘汰。
LFU算法的实现
前面LRU使用了一个hash表+一个双向链表,hash表中存储了key值对应的具体node节点,node节点之间组成了一个双向链表,这样既提高了查询效率,又提高了操作效率。同样作为内存淘汰算法,LFU也需要使用类似的数据结构实现,不过LFU算法淘汰数据是基于使用频率的,所以,我们需要快速找到同一频率的所有节点,然后按照需要淘汰掉最久没被使用过的数据。所以,首先我们要有一个hash表来存储每个频次对应的所有节点信息,同时为了保证操作效率,节点与节点之间同样要组成一个双向链表,得到如下结构:

hash表中的key表示访问次数,value就是一个双向链表,链表中所有节点都是被访问过相同次数的数据节点。可以看到,相比较于LRU算法中的节点信息,LFU算法中节点的要素中除了包含具体的key和value之外,还包含了一个freq要素,这个要素就是访问次数,同hash表中的key值一致。这样做的好处是当根据key查找得到一个节点时,我们可以同时得到该节点被访问的次数,从而得到当前访问次数的所有节点。
有了LFU算法的主体结构之后,我们发现还缺少一个重要功能,就是如何根据key值获取value值。所以,参考LRU算法的数据结构,我们还需要有一个hash表来存储key值与节点之间的对应关系。最终,我们就可以得到LFU算法完整的数据结构:
- 基于上面的数据结构,我们就可以实现完整的LRU算法功能。首先看下查询数据的get操作的具体逻辑:
- 如果key不存在返回null;
- 如果key存在,则返回对应节点的value值。同时,需要将节点的访问次数+1,然后将该节点从原双向链表中移除,添加到新的访问次数对应的双向链表中。注意:如果原来访问次数对应的双向链表在移除该节点之后,只剩下了head节点和tail节点,说明没有真实的业务数据节点存在,则需要从访问次数hash表中移除这个链表。
- put操作的具体逻辑:
- 如果key已经存在,则更新对应节点的value值,然后将该节点的访问次数+1,然后将该节点从原双向链表中移除,添加到新的访问次数对应的双向链表中。注意:如果原来访问次数对应的双向链表在移除该节点之后,只剩下了head节点和tail节点,说明没有真实的业务数据节点存在,则需要从访问次数hash表中移除这个链表。
- 如果key不存在,则执行新增数据的动作:如果还未达到最大容量,则插入新的数据节点。节点的访问次数为1,如果hash表中不存在对应的双向链表则需要先创建链表;如果超过了最大容量,则需要先删除访问次数最低的节点,再插入新节点。节点的访问次数为1,如果hash表中不存在对应的双向链表则需要先创建链表。
本地缓存组件的其他关注点
淘汰策略是缓存组件的一个很重要的关注点,直接关系到缓存的命中率。上面只是简单的介绍了两个淘汰策略的实现,看完就已经够让人掉头发的了。然而,要手动实现一个本地缓存组件,除了淘汰策略还要考虑其他问题:
- 存储;并可以读、写;
- 原子操作(线程安全),如ConcurrentHashMap
- 可以设置缓存的最大限制;
- 超过最大限制有对应淘汰策略,如LRU、LFU
- 过期时间淘汰,如定时、懒式、定期;
- 持久化
- 统计监控
简单的一个Map肯定是无法实现上述功能的,需要我们充分考虑各种需求,然后去实现。有如下几种选型方案:
本地缓存方案选型
使用ConcurrentHashMap实现本地缓存
缓存的本质就是存储在内存中的KV数据结构,对应的就是jdk中线程安全的ConcurrentHashMap,但是要实现缓存,还需要考虑淘汰、最大限制、缓存过期时间淘汰等等功能;优点是实现简单,不需要引入第三方包,比较适合一些简单的业务场景。缺点是如果需要更多的特性,需要定制化开发,成本会比较高,并且稳定性和可靠性也难以保障。对于比较复杂的场景,建议使用比较稳定的开源工具。基于Guava Cache实现本地缓存
Guava是Google团队开源的一款 Java 核心增强库,包含集合、并发原语、缓存、IO、反射等工具箱,性能和稳定性上都有保障,应用十分广泛。Guava Cache支持很多特性:- 支持最大容量限制
- 支持两种过期删除策略(插入时间和访问时间)
- 支持简单的统计功能
- 基于LRU算法实现3. Caffeine
Caffeine是基于java8实现的新一代缓存工具,缓存性能接近理论最优。可以看作是Guava Cache的增强版,功能上两者类似,不同的是Caffeine采用了一种结合LRU、LFU优点的算法:W-TinyLFU,在性能上有明显的优越性。也是接下来重点介绍的技术。
Caffeine
Caffeine的底层数据存储采用ConcurrentHashMap。因为Caffeine面向JDK8,在jdk8中ConcurrentHashMap增加了红黑树,在hash冲突严重时也能有良好的读性能。Caffeine是Spring 5默认支持的Cache,可见Spring对它的看重,Spring抛弃Guava转向了Caffeine。
Quick Start
在 pom.xml 中添加 caffeine 依赖:
1 | <dependency> |
创建一个 Caffeine 缓存(类似一个map):
1 | Cache<String, Object> manualCache = Caffeine.newBuilder() |
常见用法:
1 | public static void main(String... args) throws Exception { |
填充策略 Population
Caffeine可以设置填充策略,填充策略是指如何在key不存在的情况下,如何创建一个对象进行返回,主要分为下面四种:
1 手动 Manual
1 | public static void main(String... args) throws Exception { |
Cache接口允许显式的去控制缓存的检索,更新和删除。
我们可以通过cache.getIfPresent(key) 方法来获取一个key的值,通过cache.put(key, value)方法显示的将数控放入缓存,但是这样子会覆盖缓原来key的数据。更加建议使用cache.get(key,k - > value) 的方式,get 方法将一个参数为 key 的 Function (createExpensiveGraph) 作为参数传入。如果缓存中不存在该键,则调用这个 Function 函数,并将返回值作为该缓存的值插入缓存中。get 方法是以阻塞方式执行调用,即使多个线程同时请求该值也只会调用一次Function方法。这样可以避免与其他线程的写入竞争,这也是为什么使用 get 优于 getIfPresent 的原因。
注意:如果调用该方法返回NULL(如上面的 createExpensiveGraph 方法),则cache.get返回null,如果调用该方法抛出异常,则get方法也会抛出异常。
可以使用Cache.asMap() 方法获取ConcurrentMap进而对缓存进行一些更改。
2 自动 loading
1 | public static void main(String... args) throws Exception { |
3 异步手动 Asynchronous Manual
1 | public static void main(String... args) throws Exception { |
4 异步自动 Asynchronously Loading
1 | public static void main(String... args) throws Exception { |
驱逐策略 eviction
Caffeine提供三类驱逐策略:基于大小(size-based),基于时间(time-based)和基于引用(reference-based)。
基于大小(size-based)
基于大小驱逐,有两种方式:一种是基于缓存大小,一种是基于权重。
1 | // Evict based on the number of entries in the cache |
我们可以使用Caffeine.maximumSize(long)方法来指定缓存的最大容量。当缓存超出这个容量的时候,会使用Window-TinyLfu策略来删除缓存。
我们也可以使用权重的策略来进行驱逐,可以使用Caffeine.weigher(Weigher) 函数来指定权重,使用Caffeine.maximumWeight(long) 函数来指定缓存最大权重值。
maximumWeight与maximumSize不可以同时使用。
基于时间 Time Based
1 | // Evict based on a fixed expiration policy |
Caffeine提供了三种定时驱逐策略:
- expireAfterAccess(long, TimeUnit):在最后一次访问或者写入后开始计时,在指定的时间后过期。假如一直有请求访问该key,那么这个缓存将一直不会过期。
- expireAfterWrite(long, TimeUnit): 在最后一次写入缓存后开始计时,在指定的时间后过期。
- expireAfter(Expiry): 自定义策略,过期时间由Expiry实现独自计算。
缓存的删除策略使用的是惰性删除和定时删除。这两个删除策略的时间复杂度都是O(1)。
测试定时驱逐不需要等到时间结束。我们可以使用Ticker接口和Caffeine.ticker(Ticker)方法在缓存生成器中指定时间源,而不必等待系统时钟。如:
1 | FakeTicker ticker = new FakeTicker(); // Guava's testlib |
基于引用(reference-based)
我们可以将缓存的驱逐配置成基于垃圾回收器。为此,我们可以将key 和 value 配置为弱引用或只将值配置成软引用。注意:AsyncLoadingCache不支持弱引用和软引用。
Caffeine.weakKeys() 使用弱引用存储key。如果没有其他地方对该key有强引用,那么该缓存就会被垃圾回收器回收。由于垃圾回收器只依赖于身份(identity)相等,因此这会导致整个缓存使用身份 (==) 相等来比较 key,而不是使用 equals()。
Caffeine.weakValues() 使用弱引用存储value。如果没有其他地方对该value有强引用,那么该缓存就会被垃圾回收器回收。由于垃圾回收器只依赖于身份(identity)相等,因此这会导致整个缓存使用身份 (==) 相等来比较 key,而不是使用 equals()。
Caffeine.softValues() 使用软引用存储value。当内存满了过后,软引用的对象以将使用最近最少使用(least-recently-used ) 的方式进行垃圾回收。由于使用软引用是需要等到内存满了才进行回收,所以我们通常建议给缓存配置一个使用内存的最大值。 softValues() 将使用身份相等(identity) (==) 而不是equals() 来比较值。
注意:Caffeine.weakValues()和Caffeine.softValues()不可以一起使用。
1 | // Evict when neither the key nor value are strongly reachable |
淘汰策略W-TinyLFU
W-TinyLFU(Window Tiny Least Frequently Used)是对LFU的的优化和加强,这也是目前Caffeine所使用的淘汰策略。
- 算法:当一个数据进来的时候,会进行筛选比较,进入W-LRU窗口队列,以此应对流量突增,经过淘汰后进入过滤器,通过访问访问频率判决是否进入缓存。如果一个数据最近被访问的次数很低,那么被认为在未来被访问的概率也是最低的,当规定空间用尽的时候,会优先淘汰最近访问次数很低的数据;
- 优点:使用Count-Min Sketch算法存储访问频率,极大的节省空间;定期衰减操作,应对访问模式变化;并且使用window-lru机制能够尽可能避免缓存污染的发生,在过滤器内部会进行筛选处理,避免低频数据置换高频数据。
- 缺点:是由谷歌工程师发明的一种算法,目前已知应用于Caffeine Cache组件里,应用不是很多。关于Count-Min Sketch算法,可以看作是布隆过滤器的同源的算法,假如我们用一个hashmap来存储每个元素的访问次数,那这个量级是比较大的,并且hash冲突的时候需要做一定处理,否则数据会产生很大的误差,Count-Min Sketch算法将一个hash操作,扩增为多个hash,这样原来hash冲突的概率就降低了几个等级,且当多个hash取得数据的时候,取最低值,也就是Count Min的含义所在。下图展示了Count-Min Sketch算法简单的工作原理:
假设有四个hash函数,每当元素被访问时,将进行次数加1;此时会按照约定好的四个hash函数进行hash计算找到对应的位置,相应的位置进行+1操作;当获取元素的频率时,同样根据hash计算找到4个索引位置;取得四个位置的频率信息,然后根据Count Min取得最低值作为本次元素的频率值返回,即Min(Count);

参考:
力扣:手写LRU